Why LLM caching is not just Redis
Every developer knows caching. You store a response, serve it on repeat, skip the expensive computation. Simple.
LLM systems break this model in three ways.
The input is inherently unstable. Natural language almost never repeats byte-for-byte. “How do I return a product?” and “What’s the return procedure?” mean the same thing, but their hashes are completely different. A traditional exact-match cache is nearly useless.
You can cache intermediate computation, not just the final result. An LLM doesn’t look up an answer — it generates one, token by token. At every step of that generation, there are intermediate mathematical states that can be preserved and reused. You’re not just caching outputs; you’re potentially caching the process itself.
Input cost is disproportionately high. In regular APIs, the expensive part is usually the downstream call — the database query, the external service. In LLMs, the expensive part is reading: the model processes your entire context before generating the first output token. A 100,000-token context at $3 per million tokens, across 1,000 requests per day, costs $300/day — just to re-read the same document over and over.
This is where the specificity of the problem comes from. We need to cache not only finished responses but intermediate computational states, distributed across multiple levels of the stack.

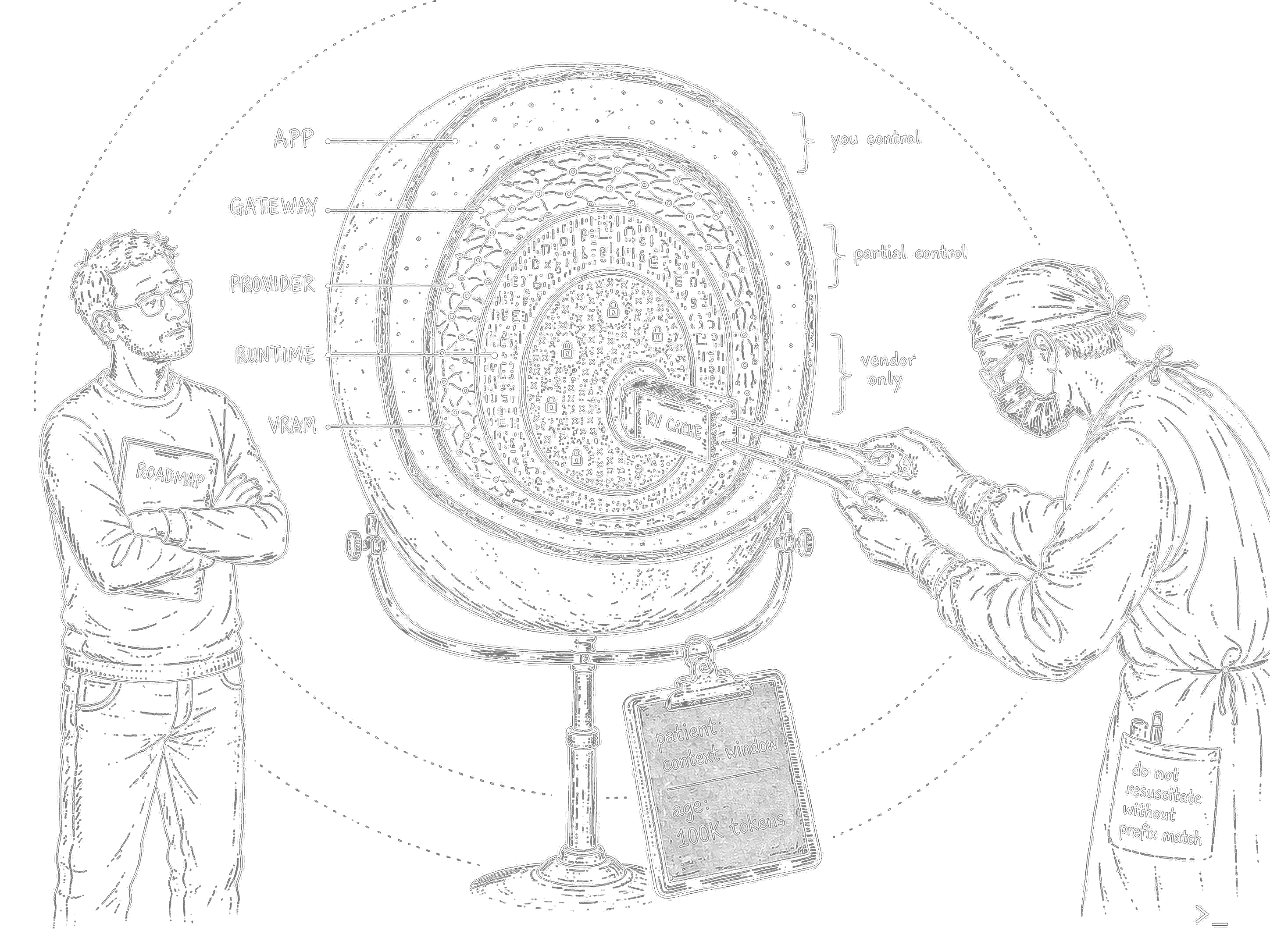
The full cache map
The deep layers — a quick tour
Everything below the provider API layer is outside your control as an application developer. But understanding what happens there matters, because it’s the foundation everything else builds on.
KV Cache is the bedrock. When a transformer generates each new token, it computes Attention across all previous tokens — a dot product of the current query against every prior key and value. Without caching, generating the 500th token means recalculating relationships to all 499 before it. The KV Cache stores those intermediate Key and Value matrices in GPU VRAM so they don’t get recomputed. Without it, long-context generation would be O(N²) in complexity. It’s always on; the provider or inference runtime controls it entirely. It doesn’t save you money directly — it’s what makes long contexts economically viable at all.
Paged Attention (vLLM, 2023) solves a different problem: the KV Cache normally occupies a contiguous block of VRAM per request, which causes severe fragmentation under concurrent load. PagedAttention breaks it into fixed-size pages, like virtual memory in an OS. Pages can be scattered across physical memory, enabling copy-on-write for beam search and dramatically better GPU utilization. Around 2–3x throughput improvement at self-hosted scale. Only relevant if you’re deploying your own models.
Disaggregated Prefill/Decode is the frontier. Prefill (computing KV for the input) and decode (generating tokens one by one) have completely different computational profiles — one is compute-bound, the other is memory-bandwidth-bound. Running both on the same GPU means each phase constantly interrupts the other. Disaggregation puts them on separate GPU pools and transfers KV state between them via RDMA. Kimi runs this in production through Mooncake. NVIDIA built Dynamo for it at GTC 2025. Meta and LinkedIn are running it with vLLM. Only relevant at hyperscaler scale.
If you want a deep technical breakdown of any of these — let me know in the comments, that’s a separate post. From here, we focus on what you can actually touch.
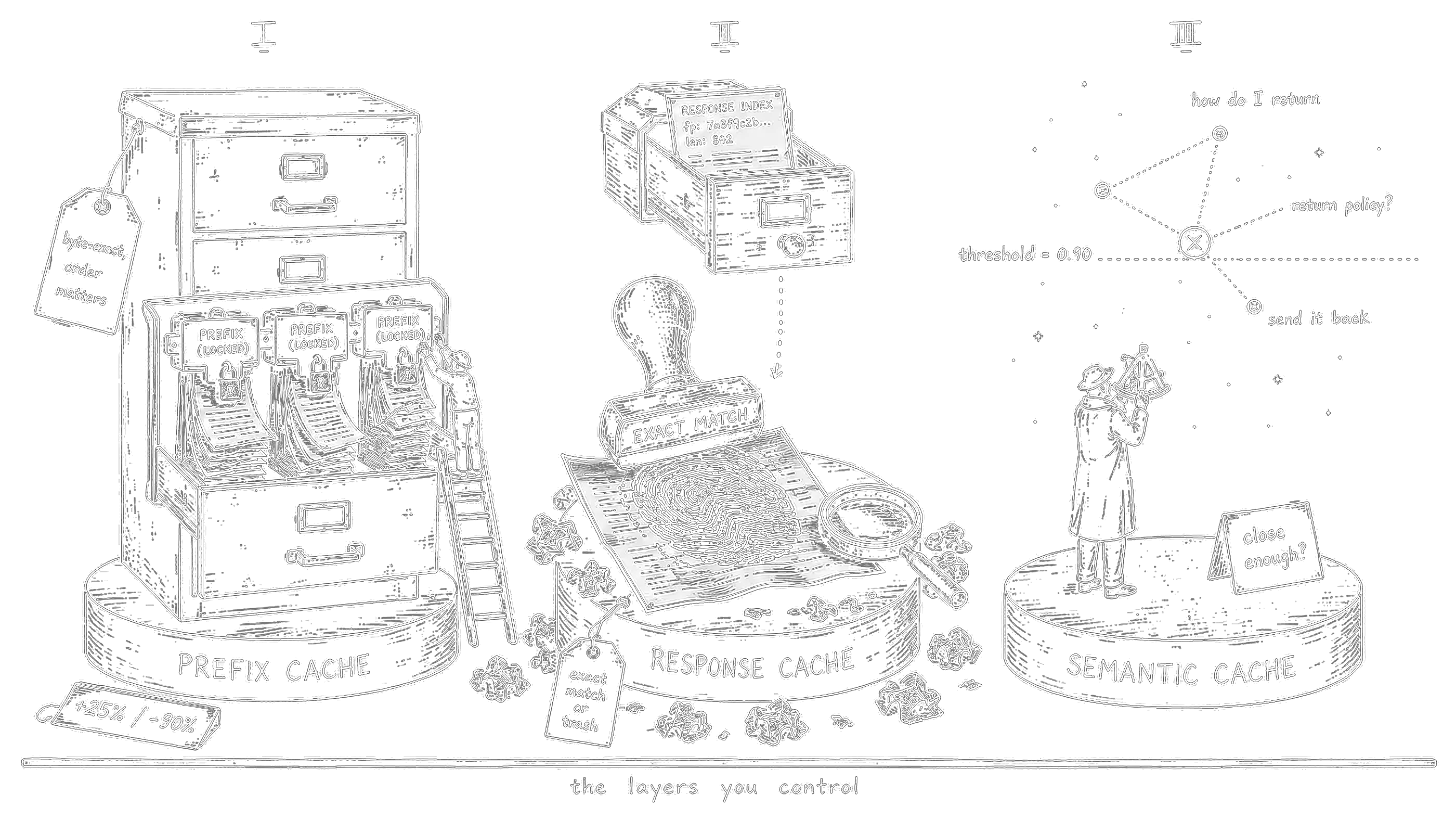
The layers you control
These three techniques live at the provider API level and above. They’re where your decisions matter.
Prefix / Prompt Caching is the highest-leverage thing most teams aren’t doing. If multiple requests share the same prefix — your system prompt, a document, tool definitions, few-shot examples — the provider stores the KV state for that prefix and doesn’t recompute it on subsequent calls. First call pays for the cache write (at Anthropic, +25% over normal input price). Every subsequent call within the TTL reads from cache at 10% of normal input price. That’s a 90% discount on the largest single line item in most LLM bills.
The constraint: this is a prefix cache, not an arbitrary one. Matching is strict, from the start of the request, byte-for-byte. Order is everything — static content must come first, dynamic content last.
The most common ways to break it without realizing: putting a timestamp anywhere in the cached section, having unstable JSON key ordering in tool definitions, injecting user context into the system prompt.
Response Cache is simpler. Aggregators like OpenRouter hash your full request (model + params + all messages). Exact match → the response comes from their edge cache, zero tokens billed. Works well in development, testing, and narrow FAQ scenarios where you genuinely send the same request repeatedly. In live production with real users, hit rate is typically under 5% — natural language variation kills it.
Semantic Cache closes the gap that exact matching leaves open. Every incoming request gets embedded into a vector, and a nearest-neighbor search checks whether a semantically similar request already has a cached response. “How do I return a product?”, “What’s your return policy?”, “I want to send something back” — same cluster, same cached answer, zero LLM calls. Tools: GPTCache (Python library, wraps your client in two lines), LiteLLM Redis semantic mode, or DIY on Qdrant/Weaviate.
The main knob is the similarity threshold. Too low (0.85) and you risk returning the wrong answer for a superficially similar but actually different question. Too high (0.95) and you’re back to near-exact matching. The vector search itself costs around 30ms and requires an embedding call, so you need at least 15–20% hit rate just to break even on the added latency.
Why should you care?
When I started posting, a few people reached out — some just to share thoughts, a couple asking for a quick look at their product. Last weekend I did my first proper orchestrator audit and gave general recommendations. Most of what we discussed I’ll keep out of this post, but one part is directly relevant here.
The product was an internal assistant with search over a large vector knowledge base. Beyond the general recommendations — better model selection for different pipeline stages, restructuring the orchestration flow, a few other things I’ll keep out of this post — caching deserved its own conversation. There was a pattern that stood out immediately: the queries to the vector store were highly repetitive. Users throughout a session would ask about the same topic with different phrasing — “show me documents about X,” “what do we have on X,” “find everything related to X.” Different words, same intent, same vector search, same retrieved context flying into the LLM every single time.
There was also toolcalling, but it happened infrequently enough that it wasn’t the priority.
What did I find:
Semantic cache before the vector store. Threshold at 0.90, BGE-M3 embedder at 512 dimensions (runs in ~2ms). Within a single session, query similarity is very high — mock tests showed around 55% hit rate.
Prefix caching on retrieved context. The context returned from the vector store is static within a topic — same documents, same chunks. Move it into the cacheable prefix, put the user’s dynamic question at the tail with a cache_control breakpoint after the static block.
Model and provider migration. Part of the broader recommendations was moving to models and providers that natively support prompt caching — which unlocks the prefix cache savings above in the first place.
The team is still working through the full list of changes, so there are no production numbers yet. What we do have are test results run against real historical queries — the actual requests users had been sending before the audit, not synthetic benchmarks:
- Average response latency: −38% (less prefill, partial cache hits)
- Input token cost: −52%
- Overall cost estimate at their volume: −44%
These numbers reflect a specific profile — high query repetition, a stable knowledge base, session-based usage. Systems with more conversational variance will see lower gains. But internal assistants, support bots, and code assistants are exactly the workloads where this profile is most common.

For teams on open-source stacks
Large enterprise teams running self-hosted infrastructure: Qwen, GLM, or DeepSeek through vLLM, open-source wrappers like ForgeCode, OpenCode, or Aider, internal orchestrators. These stacks have no provider-level prompt caching — there’s no provider. NDAs or internal policies block external commercial services.
The math is straightforward. 50 developers at $200/month in LLM spend is $10,000/month. Cut that by 50% and you save $5,000/month. One engineer-week to implement pays for itself in the first month.
How to actually do it: ForgeCode or nano-claude-code
ForgeCode (forgecode.dev, Apache-2.0, Rust) sits at #1 on TermBench 2.0 with 81.8% accuracy — ahead of Claude Code’s 58% and OpenCode’s 51.7% on that benchmark. Despite this, it has no caching layer of its own. It relies entirely on provider-level prompt caching and careful context structuring. Everything is open for modification.
The no-fork path via LiteLLM proxy gives you response cache and basic semantic cache. But it only operates on the response level — you have no visibility into the agent context, which queries are being made, or what’s worth caching at the tool or planning stage. It’s a start, not a solution.
The real path is forking crates/forge_agent/ and adding a cache layer directly into the agent loop. The SAGE agent — ForgeCode's read-only research agent for codebase understanding — is the right first target. Its queries are maximally repetitive (the same architectural questions about the same codebase), and a wrong cache hit has low consequences since it's read-only. What to add: semantic cache lookup before every API call, cache write only on successful outcomes, version tag in every cache key so that adding or removing tools automatically invalidates stale entries.
nano-claude-code (Python, ~5,000 lines, MIT) is a clean-room reimplementation built from public analysis of Claude Code’s architecture after the source leak. It supports 20+ models, includes a multi-agent setup and a memory system. If your team is on Python, this is a lower-friction entry point — adding a cache layer in Python is considerably simpler than in Rust, and the codebase is small enough to fully understand in a day.
Both are better treated as engineering learning exercises and architectural explorations than production replacements. But for large teams with the right workload profile, the ROI is real.
To wrap up
The cache map in one sentence: KV Cache and everything below it is infrastructure you benefit from but don’t control; prefix caching is the single highest-ROI change most teams haven’t made yet; semantic cache pays off in specific high-repetition workloads; the interesting open problem is adding proper caching to open-source agent frameworks.
Things that catch people off guard:
Caches go stale on semantics, not time. Add a new tool to your orchestrator and your entire Tool Selection Cache is invalid. Use version tags in cache keys: tools:v3:{hash}. Otherwise you're serving yesterday's routing decisions.
Compaction is a hidden budget killer. When the context window fills up, Claude Code forks a separate summarization call with a different system prompt. The cache prefix diverges at token zero — no cache hits. The longer the session, the more expensive that single call. If you’re building something similar, cache compaction results locally keyed on a hash of the conversation.
Semantic cache and personalization don’t mix. “Show me my orders” from user A and user B are semantically identical. Always scope your cache key to include user identity, or disable semantic cache entirely for personalized requests.
The most expensive token is the one you paid for twice.
