1. Origins and philosophy
Anthropic was founded in 2021 by ex-OpenAI researchers who left over how seriously safety should be prioritized — and that one fact explains almost every product decision since. Constitutional AI became the technical core, but the more important consequence was cultural: Anthropic ended up enterprise-first from day one, with ~80% of revenue from API and enterprise versus ~30% for OpenAI. Same industry, fundamentally different companies.
The thesis of this article: Anthropic was never trying to win the model race. They’ve been building for a different game — the infrastructure layer of the agentic era — and once you see that, everything else clicks into place.
2. The infrastructure bet — MCP, Skills, and the logic of standards
The clearest evidence of Anthropic’s strategy isn’t a model release. It’s a protocol.
In November 2024, Anthropic open-sourced MCP (Model Context Protocol) — a standard for how AI agents connect to tools and data. Within a year, OpenAI, Google, and dozens of smaller players adopted it. MCP is now the de-facto industry standard.
Other companies tried this and failed. OpenAI shipped Plugins in March 2023 — same problem, dead within a year. Google had internal frameworks that never made it into a portable spec. LangChain built abstractions but stayed library-shaped, not protocol-shaped. So why did MCP work where Plugins didn’t?
Three reasons. First, MCP shipped as an open spec, not a product. Plugins were tied to ChatGPT — adopting them meant adopting OpenAI’s runtime. MCP is just a protocol; you can implement it with zero Anthropic dependency, which made it safe for competitors to adopt. Second, the design is genuinely model-agnostic. Plugins were shaped around how GPT-4 wanted to be prompted; MCP treats the AI as one consumer of a standard interface, not the center of the universe. Third — and this is the strategic insight — Anthropic understood that controlling the protocol matters more than owning what’s built on it. You don’t need to own the cars when you own the road.
Skills is the newer move. MCP standardizes tool integration; Skills standardizes agent behavior — packaging domain expertise into reusable, versioned units. Think npm for agents. Adoption hasn’t crossed MCP’s threshold yet, but the play is identical: define the standard, give it away, win the layer above.
The business logic underneath is unintuitive but important. Open standards aren’t altruism — they’re how you monetize the infrastructure position. When Cursor uses Claude as default, Anthropic earns inference on every keystroke. When an enterprise wires MCP servers across their stack, they’re locked into the ecosystem even though the model is technically swappable. The protocol creates the gravity. The model collects the rent.
3. The hype wave — how Claude Code captured developer mindshare
Late 2025 through early 2026, something organic happened that no marketing budget could engineer.
Claude Code went from niche CLI utility to one of the most-discussed dev tools online. Cursor made Claude its default. Twitter became a continuous stream of screenshots — concurrency bugs solved in one shot, fifty-file refactors completing successfully, agentic loops running unattended for hours and producing usable PRs. The partner numbers backed up the social-media noise: Cursor reported 70% on its internal CursorBench versus 58% for the previous Claude generation. Rakuten reported 3× more production tasks resolved.
A second, quieter pattern: people just like talking to Claude. Across forums and casual conversation, the same sentiment repeats — Claude feels more thoughtful, less sycophantic, more willing to push back. This is partly Constitutional AI training (genuinely less optimized to flatter), partly cultural — Anthropic resisted turning Claude into a cheerful brand mascot. The result is a smaller but more loyal user base that often sticks with Claude even when GPT or Gemini score higher on specific benchmarks.
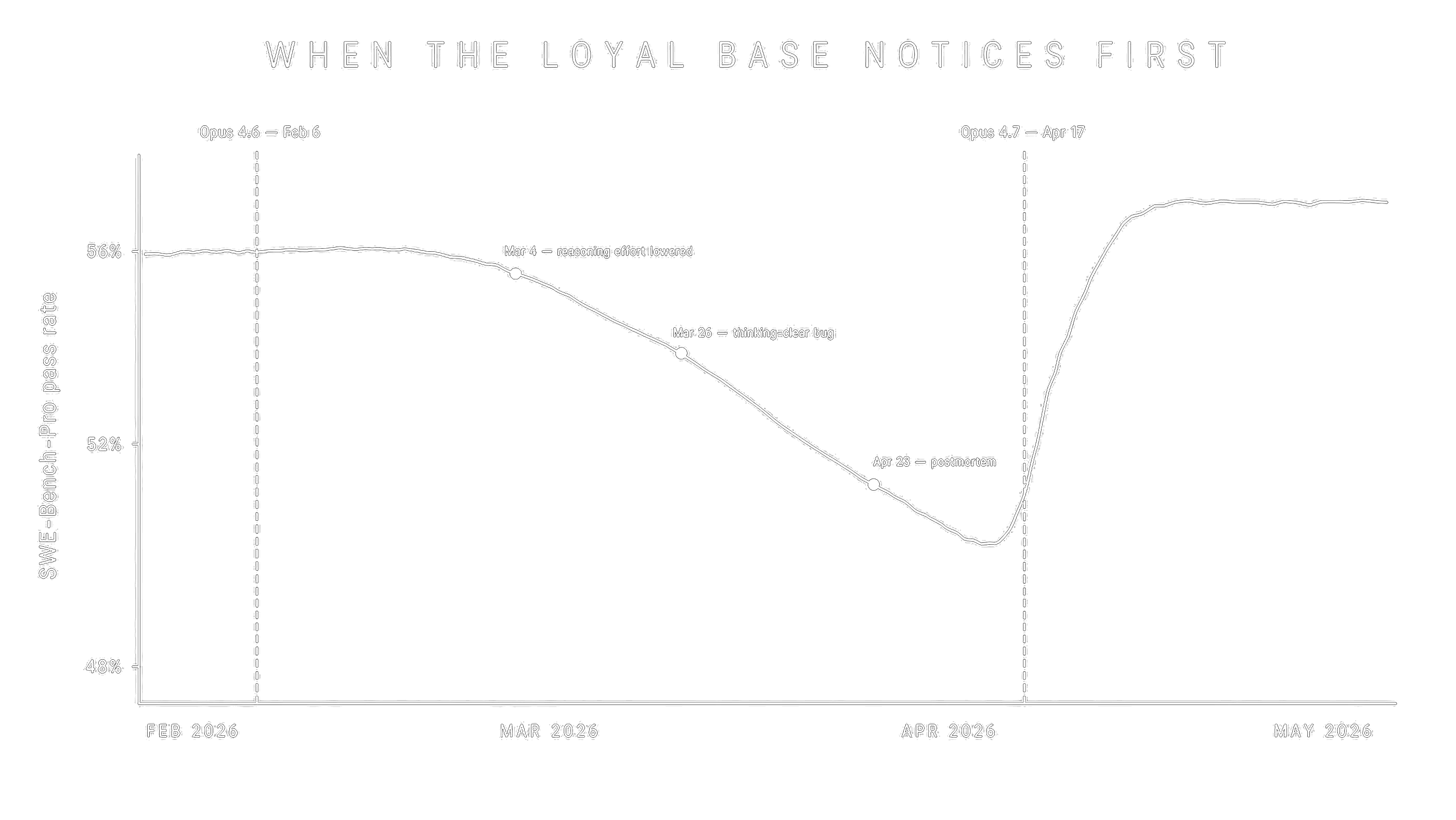
But the hype wave came with a hidden cost. When Opus 4.6 visibly degraded in March-April 2026 — Marginlab measured a drop from 56% to 50% pass rate on SWE-Bench-Pro, confirmed by Anthropic’s own April 23 postmortem citing three concurrent bugs — the user reaction was disproportionately sharp. Same loyal base that elevated Claude Code now flooded the same channels with frustration. The bar had been set so high that any regression felt like betrayal. That’s the structural cost of strong fan culture: when your base is smaller and more committed, every operational stumble lands harder.
4. The current state — what they captured, what they conceded
Now the honest scorecard.
Claude doesn’t top any single category that defines a generalist frontier model — but it’s the only flagship that’s consistently in the top tier of every category that matters. That distinction is the whole story.
Look at the breakdown. GPT-5.5 wins on Terminal-Bench (82.7% vs Claude’s 69.4%), wins on raw speed and tool-call efficiency, wins on greenfield code generation. Gemini 3.1 Pro wins on context length (2M tokens), wins on multimodal reasoning, wins on cost — half the price of Claude. Both have categories where they lap Claude clearly.
But both also have categories where they collapse. Gemini is genuinely weak at coding agents and tool orchestration — it commits confidently to wrong interpretations of ambiguous prompts, and its tool-calling reliability trails the field. GPT-5.5 is fast but less careful; teams running it in production agentic pipelines report higher rework rates and weaker self-regulation around destructive actions. Neither is a universal model.
Claude is. On SWE-bench Pro, Claude leads (64.3% vs GPT-5.4’s 57.7% and Gemini’s 54.2%). On MCP-Atlas, the most important agentic-tool benchmark, Claude leads (77.3% vs Gemini’s 73.9% and GPT-5.4’s 68.1%). On computer use (OSWorld), Claude leads (78.0% vs GPT-5.4’s 75.0%). On reasoning (GPQA Diamond), Claude is in a three-way tie with the other flagships at ~94%. Even where it doesn’t lead, it doesn’t fall off — it sits in the top tier of every category. This is what universality looks like, and no other flagship has it right now.
Then there’s a second-order effect that compounds the universality advantage. Because Anthropic defines the agentic infrastructure, models trained against that infrastructure win the integration layer by default. MCP, Skills, computer use, agent loops — these are all standards Anthropic shaped, and Claude is trained natively against them. Other models had to retrofit support. When you measure tool-calling reliability or multi-step agentic orchestration, Claude isn’t just “good at tools” — it’s good at the specific tools and patterns the industry standardized on, because Anthropic standardized them.
There’s also Grok, which doesn’t fit the frontier comparison cleanly but is the best model for the money — significantly cheaper and still usable for most tasks. If raw cost-per-token is the constraint, Grok is the answer, not Claude.
Captured:
- Universal flagship coverage. Top tier across coding, tool use, computer use, reasoning. The only flagship without a major weakness.
- Applied coding through agents. Strong instruction-following, low hallucination on tool calls, native MCP — Claude is the default for IDE and CLI agents.
- MCP as standard. Most durable win of all. Even if Claude’s quality slipped further, MCP would remain — and any model running through MCP-shaped infrastructure inherits an advantage Claude was trained for.
- Regulated B2B verticals. Finance, legal, medical. Constitutional AI and Anthropic’s safety posture are competitive moats here, not marketing.
- Developer mindshare. Hard to monetize directly, but it’s the funnel into enterprise contracts.
Conceded:
- Mass-consumer chat. ChatGPT outpaces Claude.ai by an order of magnitude in DAU. Deliberate non-investment, but the cost is real.
- Web-research agents. On BrowseComp, Claude trails Gemini and GPT by 5–10 points.
- Multimodal frontier. Vision improved in 4.7, but Gemini remains ahead on cross-modal and video.
- Pure content generation. GPT has the edge for long-form creative and marketing.
- Price competitiveness. At $5/$25 per million tokens, Claude is the most expensive of the three flagships. Gemini is half the price. For high-volume general-purpose work, Claude isn’t the rational choice.
- Claude.ai itself. No voice input. Long-running bugs in thinking and tool-call animations. Voice mode unstable. Power users moved into wrappers — Cursor, Claude Code, direct API. The platform develops on residual resources.
- Operational maturity. Two public postmortems in seven months. The Opus 4.6 reasoning-effort regression took 34 days to revert. This is the weakest link in the strategy, because every ops failure undermines the trust B2B contracts depend on.

The Endgame
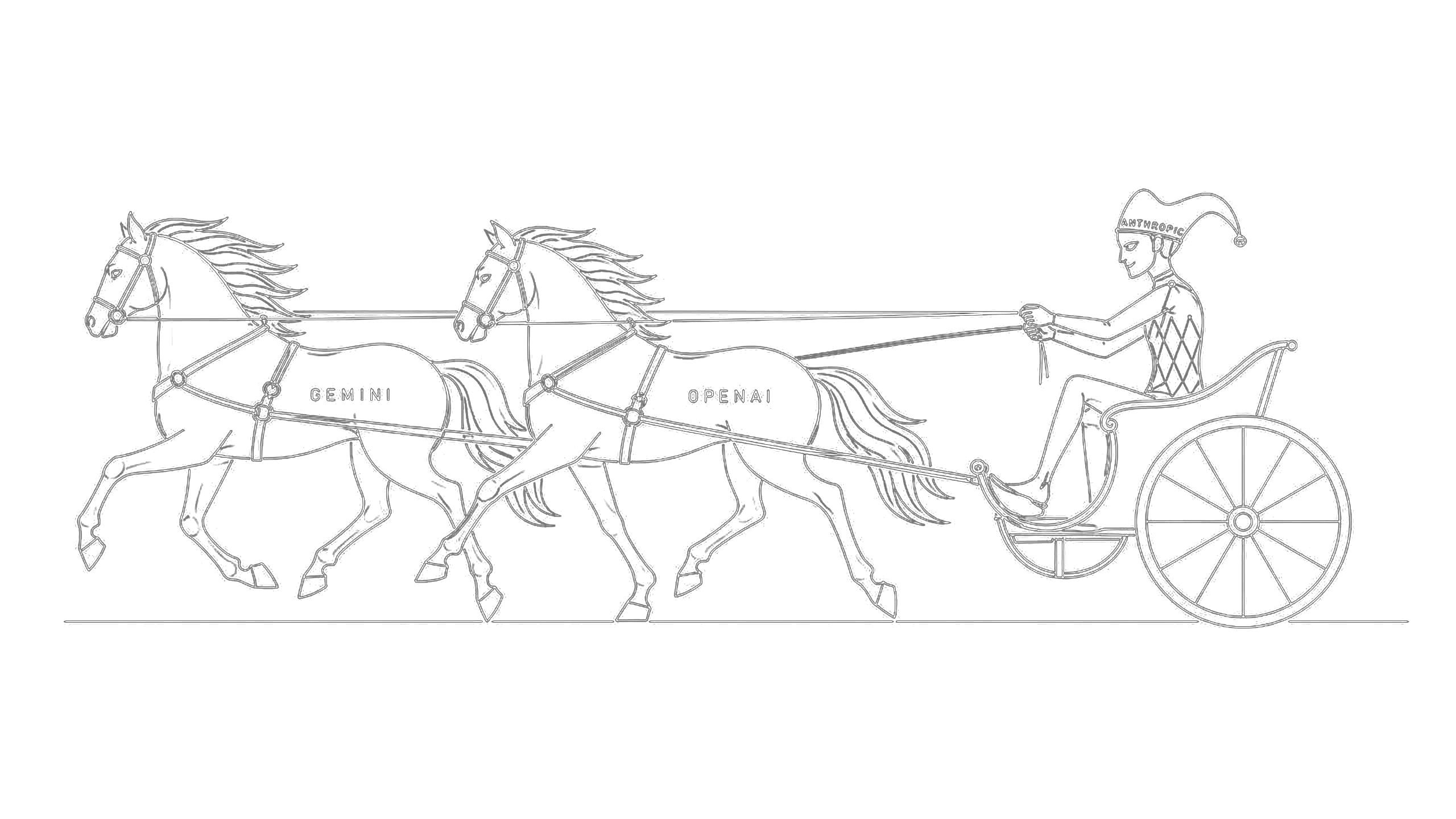
Here’s the metaphor that locks the whole picture into place. Claude isn’t the strongest engine on the road. Gemini and GPT are bigger, faster, more powerful in raw horsepower terms. But Claude isn’t trying to be the engine. Claude is the carriage. Anthropic builds the road, the harness, the reins, the wheels — the entire apparatus through which engines pull useful work. The models are interchangeable; the infrastructure is not.
This is why the model-by-model comparison misses the point. When an enterprise wires its agentic stack through MCP, defines its workflows in Skills, and runs its dev environment through Claude Code — the cost of swapping the underlying model approaches zero, but the cost of swapping the infrastructure approaches infinite. Anthropic positioned themselves as the layer that controls how models are harnessed, not as the strongest model. That’s a structurally more durable place to stand than any single benchmark lead.
But the metaphor cuts both ways. Carriages need engines. If Claude falls two generations behind Gemini and GPT, the carriage starts looking like dead weight — and enterprises will hitch the same MCP harness to faster horses. Microsoft and Google can absorb the standards into their own clouds and run their own engines against them, turning Anthropic’s protocol gift into a competitive disadvantage. The surface area is exposed.
Two or three years from now, one of two outcomes. Anthropic becomes the default carriage of the agentic era — the AWS for agents — and earns rent on every workload that moves through the standards they shaped. Or competitors copy the harness, out-execute on operations, and Anthropic ends up as a niche provider with elegant infrastructure and a loyal but shrinking base. Which one lands won’t be decided by benchmarks. It’ll be decided by how quickly bugs get fixed, whether the standards stay open without Anthropic at their center, and whether the company finally invests in the consumer surface it has been content to neglect.
The model race was never the game. The infrastructure race is. And the carriage is still ahead — for now.
